Over the course of my last project, I found myself examining many of my own implicit assumptions about testing. I’d like to explore some of them today and share what I’ve learned.
What is a test?
This is a simple question, but the first time I heard it posed was a couple weeks ago, while watching Kent C. Dodd’s Assert.js workshop from 2018:
Kent C. Dodds talks about testing software
I was actually befuddled by this question, because I’d never thought about it! Up until mid December, the way I thought about tests was primarily in terms of frameworks and levels of the test pyramid.
My immediate response (since this was at a JavaScript conference) was “it’s a thing you write in Jest, or Mocha, or some other test framework, to check if your code is working.” The problem with this definition is that it’s circular: What is Jest? Jest is a test framework. What is a test framework? It’s a thing that helps you run tests. What is a test? A test is a thing you write in Jest or some other framework…
A test is code that throws an error when the actual result of something does not match the expected output.
Personally, I would go even further and argue that throwing an error is an implementation detail (although an extremely useful detail, as we’ll see in the next blog post or two). From a technical perspective, a test is simply a bit of code that, when run, tells you something about whether some other part of your code (the subject under test) is working as intended.
This test code doesn’t have to be run inside a test framework, it doesn’t have to use an assertion library, it doesn’t have to do any fancy things like calculate test coverage, take snapshots, or even print out a test summary.
The funny thing is, I knew this implicitly. I just finished the Introduction to Computer Systems class in my part-time degree program, and in our C programming assignments we were exhorted to write tests. And yet, in the course, there was no expectation that we would use a test framework or assertion library to do so (I don’t think the words “test framework” or “assertion library” were ever uttered in the course).
So what did I do? During development, I stuck code like this directly in main():
// this...// 1 is a pass, 0 is a failprintf("%d\n",expected==actual);// ... or this...printf("Expected: %s\n",expected);printf("Actual: %s\n",actual);// ... or this!if(actual!=expected){printf("ERROR!!!!!!!!!1!1!!11!!!\n");printf("Expected: %s\n",expected);printf("Actual: %s\n",actual);}
Those were my tests, and because I never needed to run more than a few at any given time, this simple setup worked perfectly fine. Nothing we wrote in class was ever complicated enough for me to need more than a few printf statements. It doesn’t take long, however, before this approach becomes unwieldy, even for simple command line applications.
This brings me to the next question: what is the purpose of writing tests?
Why write tests?
The question “why test?” is a simple one to answer. We test software so that we know if it works the way it’s supposed to.
The question “why write tests?” is not the same question as “why test?” It’s a small but subtle difference: writing tests implies automated testing against a specification, while “why test?” does not.
Sure, we often talk about automated testing as giving us confidence in our code – and yet, how often does code go into production without any manual testing whatsoever? Rigorous testing in general is what gives us confidence in our code, and automated testing is just one dimension of that.
This means that writing tests requires an additional layer of justification. Test automation is not free: it costs developer time, as any stakeholder desperate to get the next release into production will tell you. A manual tester can do everything that an automated test can do, and a manual tester can also do many things that an automated test cannot do.
So why write tests?
The purpose of writing tests is to get fast feedback. This is the principle that justifies the economic cost of writing tests. It’s an investment of time that pays back dividends in the shorter time it takes to detect bugs, allowing developers not to lose context during debugging or refactoring, and freeing up developer and QA time for higher-value activities.
You know this, I know this, and we still struggle to convey the full impact that good test coverage has on development. We often frame writing tests as “providing confidence in our code”, which is true, but as I mentioned above, automated testing is not the only way to be confident that our code performs to spec. The real reason for test automation is that this confidence can be provided quickly.
This is also the reason that the test pyramid looks the way it does, with unit tests forming the base and E2E tests at the top. If we have E2E or functional tests that mimic an entire user journey, why do we even need unit tests? After all, E2E tests are the tests that give us the greatest confidence that the application performs as expected – but E2E tests also impose a lot of overhead, have many potential points of failure, and take more time to run. We use unit tests because unit tests give us faster feedback.
(An aside: if we want fast feedback, why do we run automated E2E tests, since they’re slow? It’s important to consider what E2E testing is, and what it’s meant to be an alternative to. Unit tests and E2E tests are not substitutes for each other. Instead, E2E tests are meant to replace repetitive manual testing, and automated E2E tests definitely give faster feedback than a human. I should know – I used to be that human.)
The value of a test suite that can run in seconds rather than minutes is the difference between refactoring being tolerable or intolerable. If you have to wait three minutes every time you refactor something minor to confirm that your tests still pass, the refactoring is not going to happen. That’s why fast tests are essential to any refactoring.
Understanding that we write tests to get fast feedback then helps us to frame how we go about writing our tests.
How do you write tests?
This section isn’t about the mechanics of writing tests. Instead, it’s about what information you need from a test in order to extract fast feedback from it.
There are three aspects of getting fast feedback from a test:
How long does it take the test to run?
How long does it take to determine whether the test has passed?
How long does it take to determine why a test failed?
I’m going to skip over the first point, for the simple reason that it’s trivially obvious that all else being equal, a faster test provides faster feedback. There’s been plenty of ink spilled elsewhere about how to write fast tests, by people much smarter and with far more experience than me.
The second point also looks trivial. What do you mean, how long does it take to determine whether the test has passed? I’ll point you up to one of my wonderful C “tests”:
// this...// 1 is a pass, 0 is a failprintf("%d\n",expected==actual);
Imagine ten of these tests:
1
1
1
1
1
1
1
1
1
How quickly can you determine that all your tests have passed?
Count again: there are only 9 outputs, and none of them are 0. Why? Which of the 10 failed silently?
This is an easy problem to solve: don’t write tests like this! Make sure you can see at a glance whether a test passed or failed, which test passed or failed, and how many tests were run. That’s part of the answer to “how do you write tests?”. You write them so that the most important information is reported most prominently:
How many tests ran, and did they all pass?
If the answer to the second question is yes, these two pieces of information are all I need to know. Anything else is gravy.
Why do we care how many tests ran? If you expected 20 tests but only 15 of them ran, a 100% pass rate could be a false positive.
If there were failures, how many were there, and what were they?
From this point, it’s an easy jump to the third point: if a test fails, you want as much relevant information as possible to determine why it failed – and nothing else.
The relevant pieces of information answer these questions:
What is the expected result?
What is the actual result?
Which line of code is the immediate cause of the test failure?
If in doubt: what is the stack trace?
The risk of adding more information into the test output (logging intermediate states, etc.) as a matter of routine is that it generally slows debugging down. Remember, the purpose of writing tests is to provide fast feedback. Every additional piece of information that is not essential to debugging a failed test is noise, and it will slow you down.
In order for a test to provide fast feedback, then, the test needs to:
Run fast (duh)
Clearly convey the most critical information about test passes and failures
That’s how to write tests: write them in such a way that they fulfill their purpose of giving fast feedback. If you’ve only ever written tests in the context of test frameworks, none of this seems groundbreaking or meaningful, but that’s probably because you’re used to getting feedback from your tests so quickly you don’t even have to think about what your test framework is doing for you.
Next: thinking about test frameworks
This is the motivation behind a test framework. A test framework gives you the tools to quickly write repeatable, automated tests that give you fast feedback.
In my next post, I want to explore the parts that make up a test framework – a “minimum viable test framework”, as it were.
Thinking about little things that I’ve done or played with recently that I am at liberty to share, here’s a fun little one using Nokogiri to solve an entirely self-inflicted problem.
Teachable Course Page, with list of lecture videos from Adrian Cantrill’s AWS Certified Solutions Architect Associate course
The lecture titles are there and so is the duration of each lecture. I wanted to get the title and duration of each into a spreadsheet, but there is no obvious way to do it. You can use an app like TextSniper which can extract text from screenshots and visual data, but since all the information I needed was actually contained in the HTML source of the Teachable course page, there was a cheaper and more interesting solution (at least more interesting to me): scrape the page.
To do this, I chose to use Ruby and Nokogiri, a Ruby gem for parsing XML and HTML strings. I could have used Python or JavaScript to do this instead, but I’m more comfortable with Nokogiri and still a Rubyist at heart.
How Nokogiri Works
The title of this section is a misnomer. I don’t know how Nokogiri works or the full extent of what it can do, I just know how to use it to find things in HTML files.
If you want to play along, you can install nokogiri using gem install nokogiri. (If you don’t have a Ruby environment set up, you may not have permission to install gems without sudo. I’m personally not a fan of running sudo gem install, but you do you.)
The workhorse of XML parsing in Nokogiri is the Nokogiri::XML module, and the Nokogiri::HTML module inherits from it. To parse HTML with Nokogiri, you simply do this:
Now that you have your Nokogiri document, you can traverse it like a graph, if that’s your thing:
putsdocument.root.name#=> prints "html"putsdocument.root.children.each{|child|putschild.name}#=> prints "head", "body"
If document is an instance of Nokogiri::HTML::Document, what is document.root an instance of?
putsdocument.root.class#=> prints "Nokogiri::XML::Element"
What about root’s children?
putsdocument.root.children.class#=> prints "Nokogiri::XML::NodeSet"
Nokogiri::XML::Element is a child of Nokogiri::XML::Node, and Node implements the Searchable interface. Searchable gives us the #css instance method, which will search this node and all its children and return a NodeSet of all the elements that match a given CSS selector.
Now we have the ability to extract HTML elements from the document based on their CSS selectors:
document.css('.select-me').eachdo|element|putselement.textend#=> Prints "Hello World"
Extracting Video Titles
Back to the problem at hand.
I saved the HTML of the Teachable page locally and studied it. The lecture titles, it turns out, are really easy to extract:
HTML code from Teachable’s course page
<spanclass="lecture-name"> AWS Accounts - The basics (11:33) </span>
All we need is to target the .lecture-name CSS selector.
I included the whole chunk of code in the image because it reveals something interesting: Teachable uses Turbolinks. That doesn’t definitively imply that Teachable is a Rails app… but it basically implies that Teachable is a Rails app.
Great: now we can get a NodeSet of all the elements containing the video titles and runtimes, and #map it to get just the text of the element.
Now lecture_names is simply an array of strings, each containing the video title and runtime:
List of video lecture titles from Cantrill’s course printed in console
Separating Title And Runtime
The next step is to identify which portion of the text is the title, and which is the runtime. For this, there is a powerful tool, loved by some and feared by most:
Regular Expressions on regexr.com
This is the view from regexr, my favourite tool for writing regular expressions. It breaks down what exactly the regular expression is parsing, highlights where the matches are, and allows you to write tests to check the regex against.
Two related regexes are needed: one regex identifies whether there is a runtime at all, and the other parses the string into a title and a runtime. I’ll spare you the part where we put the regex together, and simply give you the two regexes:
They’re not semantically perfect. time_regex will match Reserved Instances (:::::) or Reserved Instances (12345), for example, but since the input data is clean, we don’t need to worry about that.
Now, given a string, we can determine if there is a video runtime listed at the end of the string:
time_regex=/\(([:\d]+)\)$/lecture_name="Serverless Architecture (12:55)"reading_name="IMPORTANT, READ ME !!"lecture_name=~time_regex#=> returns 24 (index where match begins)reading_name=~time_regex#=> returns nil
Once we know which strings contain video titles and which ones contain titles of readings, we can perform the match:
title_time_regex=/(?<title>.+)\s\((?<time>[:\d]+)\)$/lecture_name="Serverless Architecture (12:55)"matchdata=lecture_name.match(title_time_regex)putsmatchdata[:title]#=> prints "Serverless Architecture"putsmatchdata[:time]#=> prints "12:55"
Putting It All Together
# nokogiri.rbrequire'nokogiri'my_file='my_file.html'document=Nokogiri::HTML(File.read(my_file))lecture_names=document.css('.lecture-name')# matches strings ending with (xx:xx), where x is a digittime_regex=/\(([:\d]+)\)$/# captures title and time from a stringtitle_time_regex=/(?<title>.+)\s\((?<time>[:\d]+)\)$/lecture_names.eachdo|lecture_name|# strips out excess whitespaceformatted_text=lecture_name.text.strip.split.join(' ')ifformatted_text=~time_regex# string contains video runtimematchdata=formatted_text.match(title_time_regex)puts"#{matchdata[:title]}\t#{matchdata[:time]}"else# string does not contain video runtimeputsformatted_textendend
Note the use of \t to separate the lecture title from the lecture time. Essentially, what this does is produce tab-separated output. Given that the goal is to import the result into a spreadsheet, TSV makes a lot of sense. CSV could work too, but we’d need to account for commas in lecture titles. TSV works just fine.
$ ruby nokogiri.rb > lecture_list.tsv
Voilà, a file that I can import into Excel or Google Sheets, and use to make a study plan.
List of video lecture titles and runtimes in Google Sheets
Here is a simple scenario: you’re writing client-side JavaScript. You query an API with a city name, and it returns with a bunch of useful information about the city, including the timezone, in this format:
{"city":"New York","timezone":-18000,}
You want to use this information to display the local date and time in that city, as a string that looks something like this:
Thu, 11 Feb 2021, 1:08 am
How do you do this?
New York City’s timezone is Eastern Standard Time, or UTC-05:00. The API gives us this information in the form -18000, or 18000 seconds behind Coordinated Universal Time (UTC). (We’re not going to worry about Daylight Savings Time, and we’ll simply assume that the API is going to give us the correct time offset in seconds when DST kicks in.)
We need to find some way of representing time in seconds, or in something that can be converted to and from seconds. Then we need to turn that number into a string.
This is a good time to explain how computers represent dates and times.
Timestamps explained
We take timekeeping for granted in 2021, but there’s a lot of maths and science and engineering that goes into keeping track of time. (Don’t believe me? Check out Jack Forster’s amazing article on horology’s Easter problem, or his equally riveting read on modern chronometer watches.) Fortunately, for our purposes, we can operate at a fairly high level of abstraction, and we don’t have to get into the nitty-gritty of timekeeping.
Broadly speaking, we need two things to keep track of time: first, we need a point in time that we can use as a reference, and secondly, we need to be able to count the time elapsed since that reference time.
The good news is that where computers are concerned, counting elapsed time isn’t a concern. Computers can count milliseconds to a high degree to accuracy — after all, your computer has a clock generator in it that oscillates billions of times a second (i.e at a frequency of several gigahertz, or whatever your processor’s clock speed is). All that remains is to know what time computers are counting from.
Enter the Unix epoch: 1 January 1970, 0:00:00:000 UTC.
In most programming languages, objects and classes that handle date and time manipulation will represent the time as a timestamp, or the number of seconds that have passed since the Unix epoch. (Because of leap seconds, that’s not strictly true, but we can ignore that corner case.)
For example, as I write this on Thursday, 11 Feb 2021 at 2:08 pm at UTC+08:00, the current Unix timestamp is 1613023705.
Human-readable dates and times
Computers are very good at counting large numbers, but humans are not. We need to turn the timestamp into something meaningful for humans. This is where JavaScript’s Date object comes in useful: we can create a new Date object by passing in a timestamp, then we’ll have access to a whole host of Date methods, including toString() and toLocaleString(), which help us convert the Date object to human-readable strings.
On my machine, this prints Mon Jan 19 1970 23:33:43 GMT+0730 (Singapore Standard Time). On yours, it might print a different number, depending on what timezone you are in. In any case, it’s clearly the incorrect time. What happened?
As it turns out, JavaScript timestamps are not calculated as the number of seconds since 1 Jan 1970 0:00:00:000 UTC, but as the number of milliseconds since that time. We’ll need to multiply our timestamp by 1000:
This prints out Thu Feb 11 2021 14:08:25 GMT+0800 (Singapore Standard Time) on my machine.
Timestamps and timezones
All right, we’re one step closer, but we need to somehow convert the time from GMT+08:00 to UTC-05:00.
Computer timestamps based on an epoch are always in UTC, with no timezone offset. This makes sense: the number of seconds that have passed at the Greenwich Meridian since midnight of 1 January 1970 is the same no matter where in the world you are.
Manipulating time is as gnarly in JavaScript as it is in actual time travel, however. MDN’s documentation for Date gives us the following innocuous warning:
Note: It’s important to keep in mind that while the time value at the heart of a Date object is UTC, the basic methods to fetch the date and time or its components all work in the local (i.e. host system) time zone and offset.
So your date is stored in UTC, but most of the Date methods will return results in the runtime’s local time zone (UTC+08:00 in my case), and you need to output date and time in a third time zone (UTC-05:00, in our example). Great.
Looking down the list of Date methods, what do we have at our disposal? toString() will always return a date and time string based on the runtime’s time zone, so that’s out. toUTCString() will always return a date and time string based on UTC, so that’s out too.
toLocaleString() accepts an options argument that lets you set the timeZone property — this could be useful to us. How do we specify the timezone we need? MDN helpfully points us to the documentation for the Intl.DateTimeFormat() constructor, which has a list of all the options that we can give to toLocaleString() for date and time formatting. Scroll down to timeZone, and let’s see what we have:
timeZone: The time zone to use. The only value implementations must recognize is “UTC”; the default is the runtime’s default time zone. Implementations may also recognize the time zone names of the IANA time zone database, such as “Asia/Shanghai”, “Asia/Kolkata”, “America/New_York”.
How can we convert { city: "New York", timezone: -18000 } into America/New_York to pass as an argument to toLocaleString()? We could use a Map and map the number of seconds offset to one of the IANA time zones…
You still need to be careful when choosing the timezones, because the IANA time zones take daylight savings into account. For example, imagine you had a Map that looked like this:
If you queried the city of Chicago during daylight savings time, the API might respond with a time offset of -18000. That corresponds to the timezone of America/New_York in your Map. toLocaleString() then applies New York’s daylight savings time offset, which is -14400 instead of -18000.
Or we could avoid IANA time zones altogether, and just math instead.
Detour: Do Not Do This
At this point, you might spot the getUTCHours() and setUTCHours() methods. getUTCHours() returns an integer between 0 and 23, representing the hour in UTC time in your Date object. For the correctDateDate object that we’ve been playing with, getUTCHours() returns 6, since it is 6 am in Greenwich, London when it is 2 pm in Singapore.
setUTCHours() takes one argument, an integer between 0 and 23, and updates the hour in UTC in your Date object.
“Aha!” you might think. “Let’s calculate how many hours we need to add or subtract, and use setUTCHours() to manually offset the time! Then let’s print using toUTCString(), so we don’t have to worry about the user’s timezone!”
constcorrectDate=newDate(1613023705*1000);consttargetTimezone=-18000;// or whatever number the API returnsconstoffsetHours=targetTimezone/3600;constutcHours=correctDate.getUTCHours();correctDate.setUTCHours(utcHours+offsetHours);correctDate.toUTCString();
This gives us Thu Feb 11 2021 01:08:25 GMT. Of course, GMT is the incorrect timezone, but we’ll have to live with it. We can easily truncate the GMT timezone out of the string if we don’t need it, or replace it with the correct timezone. Perfect solution!
Wrong.
Leaving aside UTC offsets that are not a full hour (e.g. Iran at UTC+03:30, India at UTC+05:30, Nepal at UTC+05:45), the first problem you run into is when utcHours + offsetHours is less than 0 or more than 23. No big deal, we can just check for those cases, right?
Now you’re in trouble, because we don’t just want to display the local time, we also want to display the local date, and now your Date object is one day ahead of or one day behind the actual local date.
Go ahead, try it with an offset that’s big enough to trigger this problem:
constcorrectDate=newDate(1613023705*1000);consttargetTimezone=-36000;// or whatever number the API returnsconstoffsetHours=targetTimezone/3600;constutcHours=correctDate.getUTCHours();letlocalHours=utcHours+offsetHours;if (localHours<0)localHours+=24;if (localHours>23)localHours-=24;correctDate.setUTCHours(localHours);correctDate.toUTCString();
This returns Thu, 11 Feb 2021 20:08:25 GMT, which is one day ahead of the actual date in Honolulu based on the timestamp that we provided to the Date object.
There’s a better solution along these lines, which is to apply the offset directly to the timestamp.
Moving through time instead of space
Let’s start over, but this time instead of trying to manipulate a Date object’s timezone, let’s just give the Date object a different timestamp altogether:
Here, we’re applying the offset of -18000 directly to the timestamp, then creating a Date object out of it. Calling toUTCString() on this Date object gives us Thu, 11 Feb 2021 01:08:25 GMT. Now we have the correct date and time, but the incorrect timezone. If you don’t need to display the timezone, you can truncate the timezone if you’re okay with the format of toUTCString(), or use toLocaleString('en-GB', { timeZone: 'UTC' }) and specify your own set of formatting options.
I must admit that this solution is not very satisfying, because of the fact that conceptually, this is not the “correct” use of the UNIX timestamp or of timezones. We aren’t moving through timezones, we’re actually moving through UTC time itself. Ideally, we would be able to store both the timestamp and our desired time offset in a single Date object, or we would be able to give toLocaleString() the time offset that we want in an alternative format (like… oh, I don’t know, the number of milliseconds?) instead of in the form of IANA time zones.
Nonetheless, if your goal is to display the time in a specific time zone that isn’t dependent on the user’s local time, this is a workable solution. I’d love to hear of any alternatives in vanilla JS.
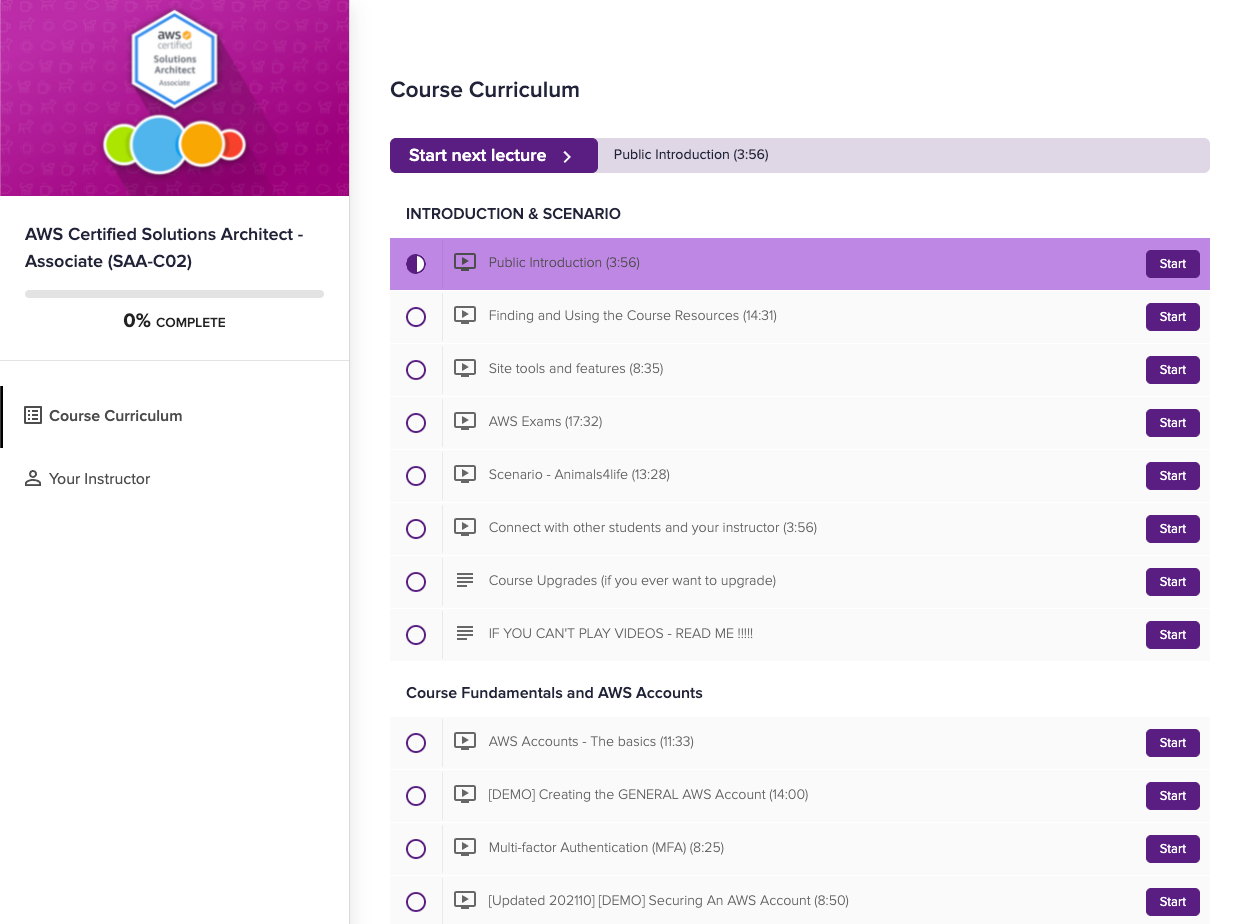 Teachable Course Page, with list of lecture videos from Adrian Cantrill’s AWS Certified Solutions Architect Associate course
Teachable Course Page, with list of lecture videos from Adrian Cantrill’s AWS Certified Solutions Architect Associate course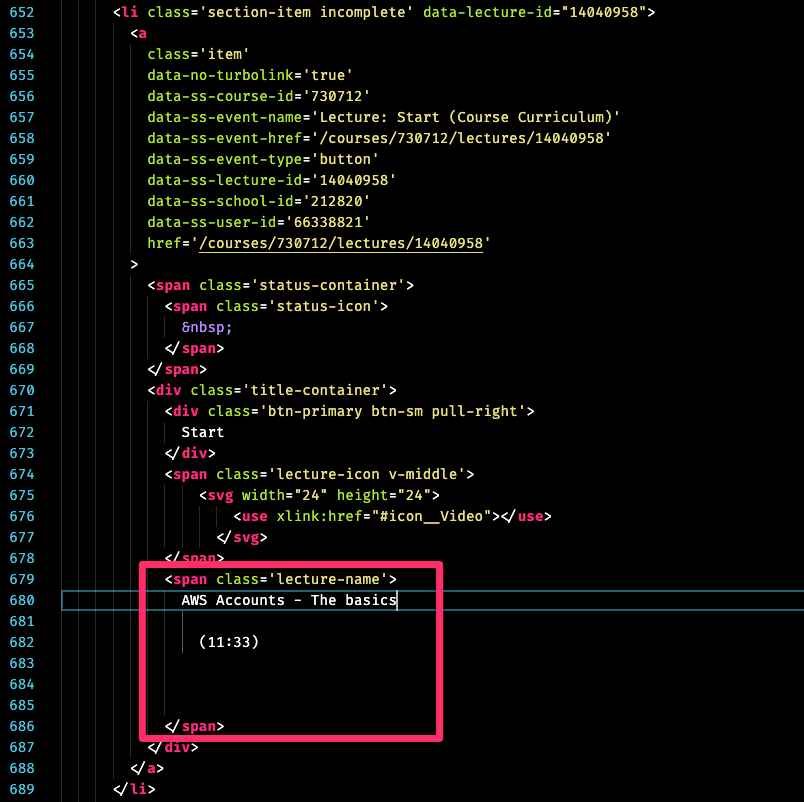 HTML code from Teachable’s course page
HTML code from Teachable’s course page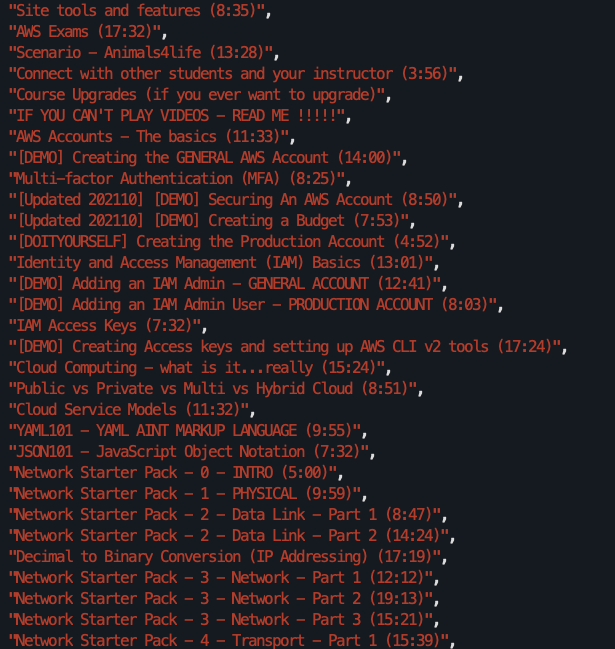 List of video lecture titles from Cantrill’s course printed in console
List of video lecture titles from Cantrill’s course printed in console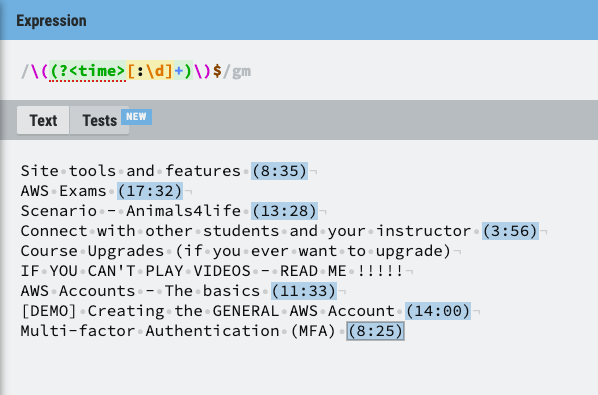 Regular Expressions on regexr.com
Regular Expressions on regexr.com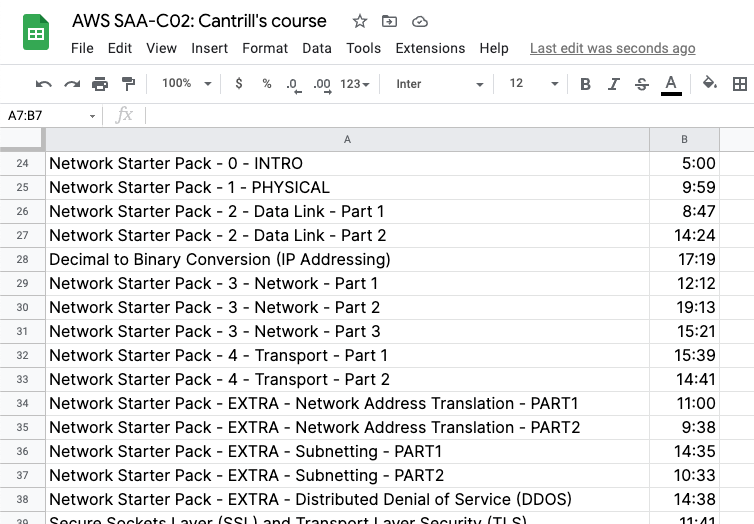 List of video lecture titles and runtimes in Google Sheets
List of video lecture titles and runtimes in Google Sheets