Scraping With Nokogiri
Thinking about little things that I’ve done or played with recently that I am at liberty to share, here’s a fun little one using Nokogiri to solve an entirely self-inflicted problem.
I purchased Adrian Cantrill’s AWS Certified Solutions Architect Associate course and wanted to break it down into smaller sections so I could plan my learning. The course is built on Teachable and looks like this:
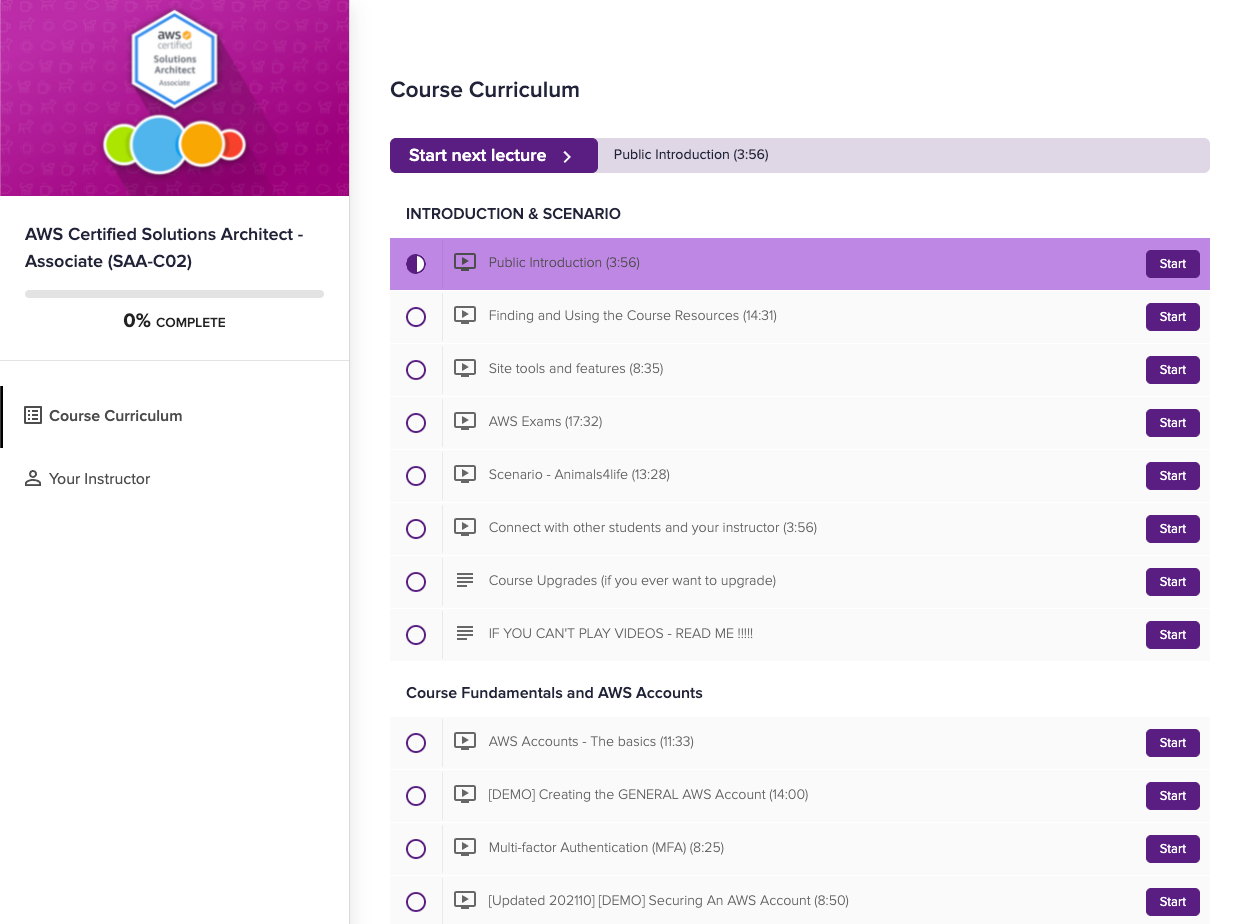 Teachable Course Page, with list of lecture videos from Adrian Cantrill’s AWS Certified Solutions Architect Associate course
Teachable Course Page, with list of lecture videos from Adrian Cantrill’s AWS Certified Solutions Architect Associate course
The lecture titles are there and so is the duration of each lecture. I wanted to get the title and duration of each into a spreadsheet, but there is no obvious way to do it. You can use an app like TextSniper which can extract text from screenshots and visual data, but since all the information I needed was actually contained in the HTML source of the Teachable course page, there was a cheaper and more interesting solution (at least more interesting to me): scrape the page.
To do this, I chose to use Ruby and Nokogiri, a Ruby gem for parsing XML and HTML strings. I could have used Python or JavaScript to do this instead, but I’m more comfortable with Nokogiri and still a Rubyist at heart.
How Nokogiri Works
The title of this section is a misnomer. I don’t know how Nokogiri works or the full extent of what it can do, I just know how to use it to find things in HTML files.
If you want to play along, you can install nokogiri using gem install nokogiri. (If you don’t have a Ruby environment set up, you may not have permission to install gems without sudo. I’m personally not a fan of running sudo gem install, but you do you.)
The workhorse of XML parsing in Nokogiri is the Nokogiri::XML module, and the Nokogiri::HTML module inherits from it. To parse HTML with Nokogiri, you simply do this:
require 'nokogiri'
document = Nokogiri::HTML('<html><head><title>Nokogiri</title></head><body class="select-me">Hello World</body></html>')
This parses the string into an instance of Nokogiri::HTML4::Document.
Since File.read and URI.open (from the open-uri library) both return a string, they can be used as sources for parsing as well:
require 'nokogiri'
file = 'parse_me.html'
document = Nokogiri::HTML(File.read(file))
require 'nokogiri'
require 'open-uri'
url = 'https://example.com/parse_me.html'
document = Nokogiri::HTML(URI.open(url))
Now that you have your Nokogiri document, you can traverse it like a graph, if that’s your thing:
puts document.root.name #=> prints "html"
puts document.root.children.each { |child| puts child.name }
#=> prints "head", "body"
If document is an instance of Nokogiri::HTML::Document, what is document.root an instance of?
puts document.root.class
#=> prints "Nokogiri::XML::Element"
What about root’s children?
puts document.root.children.class
#=> prints "Nokogiri::XML::NodeSet"
Nokogiri::XML::Element is a child of Nokogiri::XML::Node, and Node implements the Searchable interface. Searchable gives us the #css instance method, which will search this node and all its children and return a NodeSet of all the elements that match a given CSS selector.
Now we have the ability to extract HTML elements from the document based on their CSS selectors:
document.css('.select-me').each do |element|
puts element.text
end
#=> Prints "Hello World"
Extracting Video Titles
Back to the problem at hand.
I saved the HTML of the Teachable page locally and studied it. The lecture titles, it turns out, are really easy to extract:
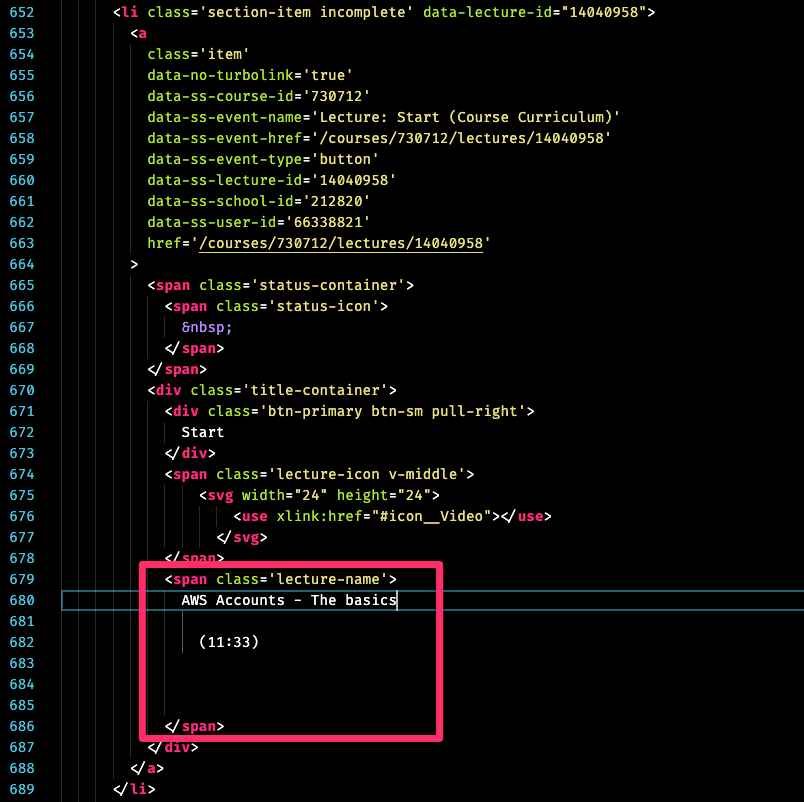 HTML code from Teachable’s course page
HTML code from Teachable’s course page
<span class="lecture-name"> AWS Accounts - The basics (11:33) </span>
All we need is to target the .lecture-name CSS selector.
I included the whole chunk of code in the image because it reveals something interesting: Teachable uses Turbolinks. That doesn’t definitively imply that Teachable is a Rails app… but it basically implies that Teachable is a Rails app.
Great: now we can get a NodeSet of all the elements containing the video titles and runtimes, and #map it to get just the text of the element.
require 'nokogiri'
my_file = 'my_file.html'
document = Nokogiri::HTML(File.read(my_file))
lecture_names = document.css('.lecture-name')
lecture_names = lecture_names.map do |name|
name.text.strip.split.join(' ')
end
Now lecture_names is simply an array of strings, each containing the video title and runtime:
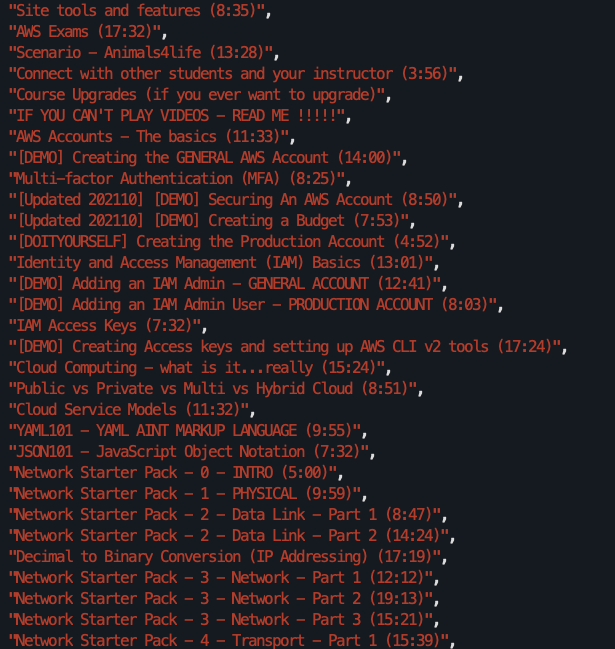 List of video lecture titles from Cantrill’s course printed in console
List of video lecture titles from Cantrill’s course printed in console
Separating Title And Runtime
The next step is to identify which portion of the text is the title, and which is the runtime. For this, there is a powerful tool, loved by some and feared by most:
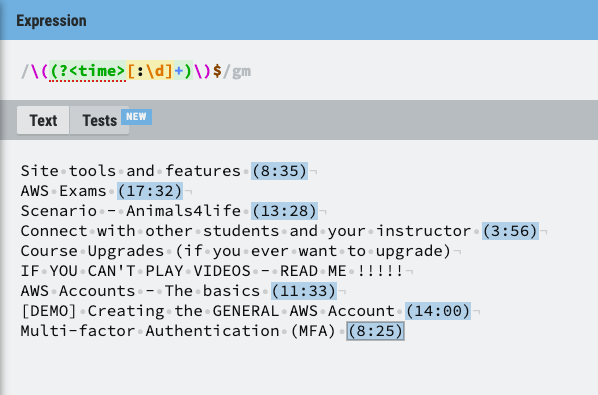 Regular Expressions on regexr.com
Regular Expressions on regexr.com
This is the view from regexr, my favourite tool for writing regular expressions. It breaks down what exactly the regular expression is parsing, highlights where the matches are, and allows you to write tests to check the regex against.
Two related regexes are needed: one regex identifies whether there is a runtime at all, and the other parses the string into a title and a runtime. I’ll spare you the part where we put the regex together, and simply give you the two regexes:
time_regex = /\(([:\d]+)\)$/
title_time_regex = /(?<title>.+)\s\((?<time>[:\d]+)\)$/
They’re not semantically perfect. time_regex will match Reserved Instances (:::::) or Reserved Instances (12345), for example, but since the input data is clean, we don’t need to worry about that.
Now, given a string, we can determine if there is a video runtime listed at the end of the string:
time_regex = /\(([:\d]+)\)$/
lecture_name = "Serverless Architecture (12:55)"
reading_name = "IMPORTANT, READ ME !!"
lecture_name =~ time_regex #=> returns 24 (index where match begins)
reading_name =~ time_regex #=> returns nil
Once we know which strings contain video titles and which ones contain titles of readings, we can perform the match:
title_time_regex = /(?<title>.+)\s\((?<time>[:\d]+)\)$/
lecture_name = "Serverless Architecture (12:55)"
matchdata = lecture_name.match(title_time_regex)
puts matchdata[:title] #=> prints "Serverless Architecture"
puts matchdata[:time] #=> prints "12:55"
Putting It All Together
# nokogiri.rb
require 'nokogiri'
my_file = 'my_file.html'
document = Nokogiri::HTML(File.read(my_file))
lecture_names = document.css('.lecture-name')
# matches strings ending with (xx:xx), where x is a digit
time_regex = /\(([:\d]+)\)$/
# captures title and time from a string
title_time_regex = /(?<title>.+)\s\((?<time>[:\d]+)\)$/
lecture_names.each do |lecture_name|
# strips out excess whitespace
formatted_text = lecture_name.text.strip.split.join(' ')
if formatted_text =~ time_regex
# string contains video runtime
matchdata = formatted_text.match(title_time_regex)
puts "#{matchdata[:title]}\t#{matchdata[:time]}"
else
# string does not contain video runtime
puts formatted_text
end
end
Note the use of \t to separate the lecture title from the lecture time. Essentially, what this does is produce tab-separated output. Given that the goal is to import the result into a spreadsheet, TSV makes a lot of sense. CSV could work too, but we’d need to account for commas in lecture titles. TSV works just fine.
$ ruby nokogiri.rb > lecture_list.tsv
Voilà, a file that I can import into Excel or Google Sheets, and use to make a study plan.
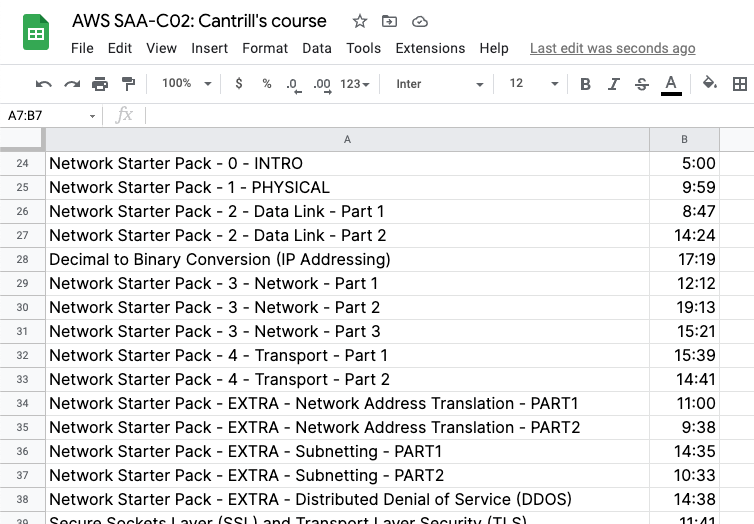 List of video lecture titles and runtimes in Google Sheets
List of video lecture titles and runtimes in Google Sheets